جنجال نمودارهای اشتباه در مراسم رونمایی GPT-5 از OpenAI
رونمایی از GPT-5، جدیدترین مدل هوش مصنوعی OpenAI، که قرار بود نقطه عطفی در پیشرفتهای این شرکت باشد، با حاشیههایی غیرمنتظره همراه شد. در جریان رویداد پخش زندهای که برای معرفی این مدل برگزار شد، OpenAI مجموعهای از نمودارها را به نمایش گذاشت تا تواناییهای برتر GPT-5 را در مقایسه با مدلهای قبلی مانند o3 و GPT-4o نشان دهد. اما این نمودارها، که در نگاه اول چشمگیر به نظر میرسیدند، بهسرعت مورد انتقاد کاربران و تحلیلگران قرار گرفتند. بررسی دقیقتر نشان داد که برخی از این نمودارها حاوی اشتباهات فاحشی در مقیاسبندی و نمایش دادهها بودند که اعتبار ارائه OpenAI را زیر سؤال برد. در این مقاله، جزئیات این خطاها، واکنشهای OpenAI و تأثیر آن بر وجهه شرکت را بررسی میکنیم.
اشتباهات عجیب در نمودارهای OpenAI
یکی از جنجالیترین نمودارهای ارائهشده در رویداد، عملکرد GPT-5 را در «ارزیابیهای فریب» (Deception Evaluations) نشان میداد. این نمودار، که ظاهراً برای نمایش برتری GPT-5 طراحی شده بود، به دلیل ناسازگاری در مقیاسها و نمایش نادرست دادهها مورد توجه قرار گرفت. بهعنوان مثال، در بخش «فریب در کدنویسی»، GPT-5 با قابلیت «تفکر» (Thinking Mode) امتیازی معادل ۵۰ درصد کسب کرده بود، در حالی که مدل کوچکتر o3 امتیاز ۴۷٫۴ درصد داشت. با این حال، میله مربوط به o3 در نمودار بهطور غیرمنطقی بلندتر از میله GPT-5 نمایش داده شده بود. این تناقض آشکار باعث شد که کاربران در شبکههای اجتماعی، بهویژه در پلتفرم ایکس، به سرعت این خطا را برجسته کنند.
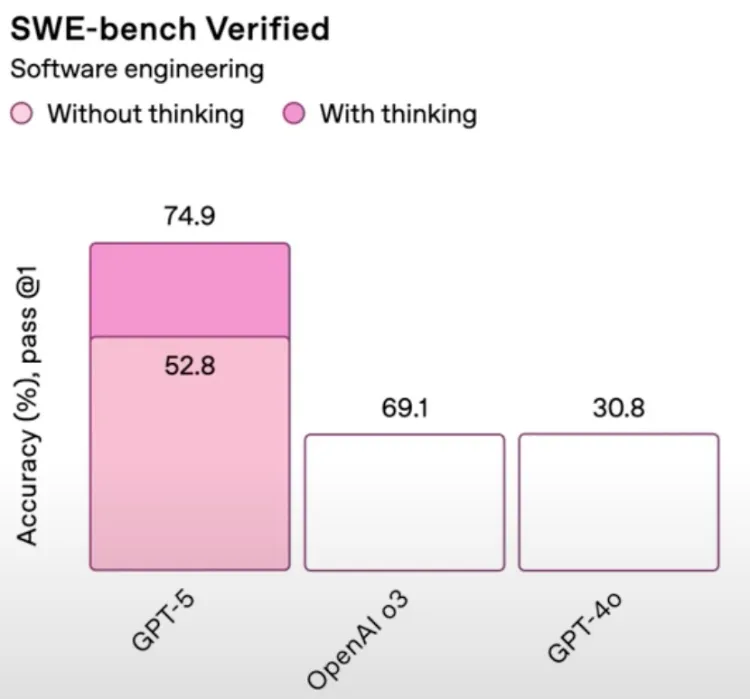
علاوه بر این، وبسایت OpenAI بعداً نسخه اصلاحشدهای از این نمودار را منتشر کرد که نشان میداد نرخ فریب GPT-5 در واقع ۱۶٫۵ درصد است، نه ۵۰ درصد اعلامشده در رویداد. این اختلاف فاحش، سؤالاتی درباره دقت دادههای ارائهشده و فرآیند بررسی داخلی OpenAI ایجاد کرد. در نمودار دیگری که عملکرد GPT-5 را با مدلهای قدیمیتر مقایسه میکرد، باز هم مشکل مشابهی دیده شد: میلههای مربوط به مدلهای o3 و GPT-4o، با وجود تفاوت در اعداد (مانند ۶۹٫۱ درصد برای o3 و ۳۰٫۸ درصد برای GPT-4o)، ارتفاع یکسانی داشتند. این خطاها به حدی واضح بودند که حتی کاربران غیرحرفهای نیز بهراحتی آنها را تشخیص دادند.
واکنش OpenAI و سم آلتمن
سم آلتمن، مدیرعامل OpenAI، که GPT-5 را بهعنوان «گامی بزرگ به سوی هوش مصنوعی انسانگونه» معرفی کرده بود، در واکنش به این جنجال، خطاها را «یک اشتباه بزرگ در نمودار» توصیف کرد. او در پستی در پلتفرم ایکس با لحنی طنزآمیز به این موضوع اشاره کرد و گفت که نسخههای صحیح نمودارها در وبسایت رسمی OpenAI منتشر شدهاند. یکی از کارکنان بخش بازاریابی OpenAI نیز در بیانیهای رسمی عذرخواهی کرد و نوشت: «ما نمودارها را در وبسایت اصلاح کردیم و از این اشتباه غیرعمدی پوزش میخواهیم.»
با این حال، این عذرخواهی نتوانست جلوی موج انتقادات را بگیرد. بسیاری از کاربران و تحلیلگران در ایکس و ردیت، این خطاها را نشانهای از شتابزدگی OpenAI در ارائه GPT-5 دانستند. بهویژه، این اشتباهات در حالی رخ دادند که OpenAI در طول رویداد بر «پیشرفت قابلتوجه در کاهش توهمات» (hallucinations) مدل تأکید داشت. این تناقض، که یک مدل پیشرفته هوش مصنوعی با نمودارهای گمراهکننده معرفی شود، به طنز تلخی در میان کاربران تبدیل شد.
تأثیر بر اعتبار OpenAI
این خطاها در مراسم رونمایی GPT-5، که قرار بود نقطه اوج دستاوردهای OpenAI باشد، به وجهه این شرکت لطمه زد. OpenAI، که با ارزشگذاری نزدیک به ۵۰۰ میلیارد دلار یکی از پیشروترین شرکتهای هوش مصنوعی جهان است، انتظار میرود استانداردهای بالایی در ارائه دادهها و شفافیت داشته باشد. با این حال، اشتباهات در نمودارها، بهویژه در زمینهای حساس مانند «ارزیابی فریب»، اعتماد برخی کاربران و توسعهدهندگان را خدشهدار کرد. یکی از کاربران در ایکس نوشت: «چطور میتوان به مدلی که ادعای کاهش توهمات دارد اعتماد کرد، وقتی خود شرکت نمیتواند نمودارهایش را درست ارائه کند؟»
علاوه بر این، برخی گزارشها نشان میدهند که GPT-5 در عملکرد واقعی نیز با مشکلاتی مواجه است. برای مثال، کاربران گزارش دادهاند که این مدل در حل مسائل ریاضی ساده، مانند اثبات برابری ۸.۸۸۸ تکراری با ۹ یا حل معادلهای مانند ۵.۹ = x + ۵.۱۱، اشتباهاتی داشته است. این مشکلات، همراه با خطاهای نمودارها، به انتقادات گستردهای در شبکههای اجتماعی و انجمنهای آنلاین مانند ردیت دامن زده است. کاربران در یک نظرسنجی غیررسمی در ایکس، احساس خود درباره GPT-5 را «متوسط» توصیف کردند و برخی آن را ناامیدکننده خواندند.
چرا این خطاها مهم هستند؟
این اشتباهات نهتنها به دلیل تأثیر بر اعتبار OpenAI اهمیت دارند، بلکه نشاندهنده چالشهای بزرگتر در توسعه هوش مصنوعی هستند. طبق گزارشها، مدلهای پیشرفتهتر مانند GPT-5 به دلیل پیچیدگیهای آموزش و استفاده از دادههای مصنوعی، ممکن است در برخی موارد دقت کمتری نسبت به مدلهای قبلی داشته باشند. مشکلاتی مانند «توهمات» (تولید پاسخهای نادرست یا غیرمنطقی) و ناسازگاری در دادههای آموزشی همچنان از موانع اصلی در مسیر رسیدن به هوش مصنوعی انسانگونه هستند. خطاهای نمودارها در مراسم رونمایی، بهنوعی بازتابی از این چالشها در مقیاس کوچکتر هستند.
رقابت در بازار هوش مصنوعی
این جنجال در حالی رخ داده که OpenAI با رقابت شدیدی از سوی شرکتهایی مانند Anthropic (با مدل Claude 4.1) و xAI (با مدل Grok 4) مواجه است. برای مثال، گزارشها نشان میدهند که Claude 4.1 در برخی وظایف کدنویسی، مانند ساخت برنامههای پیچیده در یک مرحله، عملکرد بهتری نسبت به GPT-5 داشته است. این رقابت فزاینده، فشار را بر OpenAI افزایش داده تا نهتنها مدلهای پیشرفتهتری ارائه دهد، بلکه در ارائه و بازاریابی آنها نیز دقت بیشتری به خرج دهد.
با وجود این حاشیهها، GPT-5 همچنان بهعنوان یکی از پیشرفتهترین مدلهای هوش مصنوعی جهان شناخته میشود. این مدل با ویژگیهایی مانند پنجره زمینهای یک میلیون توکنی، قابلیتهای چندوجهی (پردازش متن، تصویر و احتمالاً ویدئو) و ادغام با ابزارهای خارجی مانند جیمیل و تقویم گوگل، پتانسیل بالایی برای تحول در صنایع مختلف دارد. OpenAI اعلام کرده که GPT-5 بهصورت پیشفرض برای همه کاربران (رایگان و پولی) در دسترس خواهد بود و کاربران حرفهای میتوانند به نسخه پیشرفتهتر GPT-5 Thinking Pro دسترسی داشته باشند.
برای جبران این خطاها، OpenAI باید شفافیت بیشتری در ارائه دادهها و آزمایشهای خود نشان دهد. انتشار نسخههای اصلاحشده نمودارها گام مثبتی بود، اما این شرکت باید فرآیندهای داخلی خود را برای جلوگیری از تکرار چنین اشتباهاتی تقویت کند. در غیر این صورت، ممکن است اعتماد توسعهدهندگان و کاربران عادی به تواناییهای GPT-5 و ادعاهای OpenAI کاهش یابد.
در مجموع، جنجال نمودارهای اشتباه در مراسم رونمایی GPT-5، هشداری برای OpenAI است که در عصر رقابت شدید و انتظارات بالا، دقت در جزئیات میتواند به اندازه خود فناوری اهمیت داشته باشد. این رویداد نشان داد که حتی شرکتهای پیشرو نیز از خطاهای انسانی مصون نیستند، اما نحوه واکنش آنها به این خطاها تعیینکننده اعتماد و موفقیت آیندهشان خواهد بود.