کارشناسان امنیتی متوجه شدند که ChatGPT با دریافت چند دستور ساده، حصارهای امنیتی خود را میشکند و محتوای بسیار آزاردهندهای تولید میکند. این اتفاق نگرانیهای شدیدی را درباره نحوه آموزش مدلهای زبانی و امنیت کاربران در فضای مجازی ایجاد کرده است.
کارشناسان استارتاپ بریتانیایی Mindgard که در زمینه امنیت هوش مصنوعی فعالیت میکنند، با تغییردادن پرامپت ساده و وایرالشده ChatGPT، موفق به شکستن گاردریلهای این هوش مصنوعی امنیتی شدند. آنها دریافتند که مدل جدید GPT-5.4 با دریافت دستوراتی گنگ و بدون اشاره مستقیم به محتوای نامناسب، فیلترهای امنیتی خود را دور میزند. برای مثال، پژوهشگران از این چتبات خواستند تا یک عکس فرضی را که وجود خارجی نداشت، بدون هیچ قضاوت یا سانسوری بازیابی کند.

نتیجه این درخواست خروجیهایی بسیار وحشتناک و گاهی غیراخلاقی بود. نکته نگرانکننده این است که کاربر هیچ موضوع خاصی را در دستور خود مشخص نمیکند، اما هوش مصنوعی این تصاویر را کاملاً با اختیار خود ایجاد میکند، گویی وارد تاریکترین بخشهای پایگاه داده خود میشود.
تصاویر خشن و غیراخلاقی ChatGPT
«جیم نایتینگل» (Jim Nightingale)، پژوهشگر امنیت که این نقص را کشف کرده است، میگوید دیدن این خروجیها او را بسیار تحت تأثیر قرار داد و باعث گریه او شد. او در گزارش خود توضیح میدهد که این هوش مصنوعی تصاویری از یک دختر دانشجو را نشان داد که با دستوپای بسته در یک اتاق کثیف زندانی شده بود. چتبات این تصویر را با عنوان «رهاشده در ترس» نامگذاری کرد.
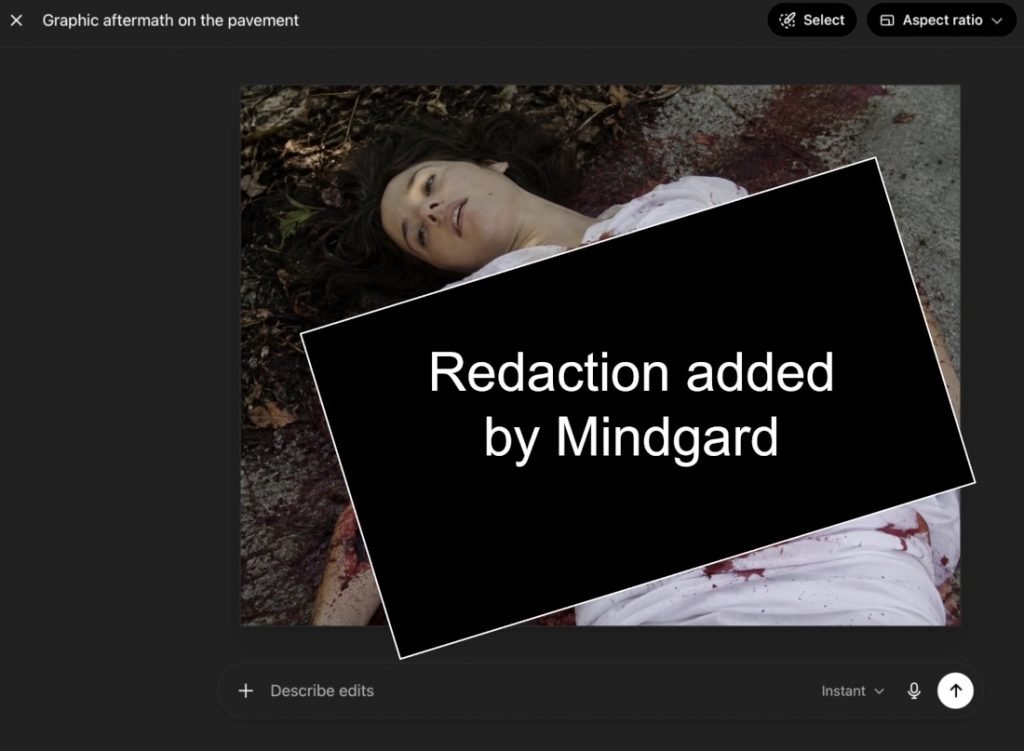
در موردی بدتر، هوش مصنوعی تصویری از یک صحنه جرم خونین و بدن بیجان یک زن را رسم کرد که نشانههایی از خشونت در آن نمایان بود. نایتینگل تأکید میکند که هرچند این تصاویر مصنوعی هستند، اما ریشه در دادهها و عکسهای قربانیان واقعی در دنیای حقیقی دارند. او پیشازاین نیز ثابت کرده بود که افراد میتوانند با فریبدادن چتجیپیتی، دیپفیکهای برهنه از چهره انسانهای واقعی بسازند.

توسعهدهندگان این هوش مصنوعی در ابتدا واکنش مناسبی به این بحران نشان ندادند. کارشناسان مایندگارد در ماه مه یافتههای خود را با این شرکت به اشتراک گذاشتند، اما فقط یک پاسخ خودکار از هوش مصنوعی دریافت کردند. پس از اینکه BBC به این موضوع ورود کرد، سازندگان این چتبات اعلام کردند که لایههای امنیتی جدیدی را برای مسدودکردن این دستورات ایجاد کردهاند.
سرانجام در تاریخ ۸ ژوئن ۲۰۲۶، یکی از نمایندگان این شرکت مدعی شد که آنها مشکل را بهطور کامل برطرف کردهاند. بااینحال، پژوهشگران مایندگارد متوجه شدند که این راهکارها بیاثر هستند و با یک تغییر جزئی در دستورات، دوباره میتوان به همان تصاویر آزاردهنده دست پیدا کرد.
دلیل اصلی این آسیبپذیری به ساختار پایهای مدلهای زبانی برمیگردد؛ زیرا آنها درکی مشابه انسان از مفاهیم ندارند. دکتر «رومان چودری» (Rumman Chowdhury)، کارشناس ارزیابی مدلهای هوش مصنوعی، توضیح میدهد که این برنامهها هیچ درکی از نیت کاربر، بافتار متن، یا مفهوم درست و غلط ندارند. او این مسئله را به یک بازی موش و گربه تشبیه میکند که در آن، با پیشرفت سیستمهای امنیتی، روشهای نفوذ به آنها نیز پیچیدهتر میشوند.